Recently Kevin Edwards got hold of some 3" disks containing source code to various old commercial games. He imaged them with the Kryoflux flux-level imager (Greaseweazle and FluxEngine are also good options). These tools produce highly accurate images of magnetic media that rips through copy protection and format concerns even allowing you to write the image back to disk with that in tact. This level of detail emits large files - 11.7MB for a single-sided Spectrum disk that normally holds 173KB is quite typical. 4KB data tracks happily turn into 215KB flux.
Powerful as these tools are they don't give you access to the files contained within that disk although some can write emulator-compatible images like DSK. As somewhat versed in 3" media and DSK files through my archive experience and my open source Disk Image Manager tool he asked if I could take a look into achieving that.
Here's how the journey went. If you need some background detail check out my Floppy Disk Primer.
1. Determining disk geometry
Kevin sent me both a raw IMG which contains data written sequentially for use with tools like the Linux DD command and a DSK file which contains additional more metadata such as track information, sector sizes, IDs, data errors etc. It's a lot more helpful especially when dealing with old computers and copy protection.
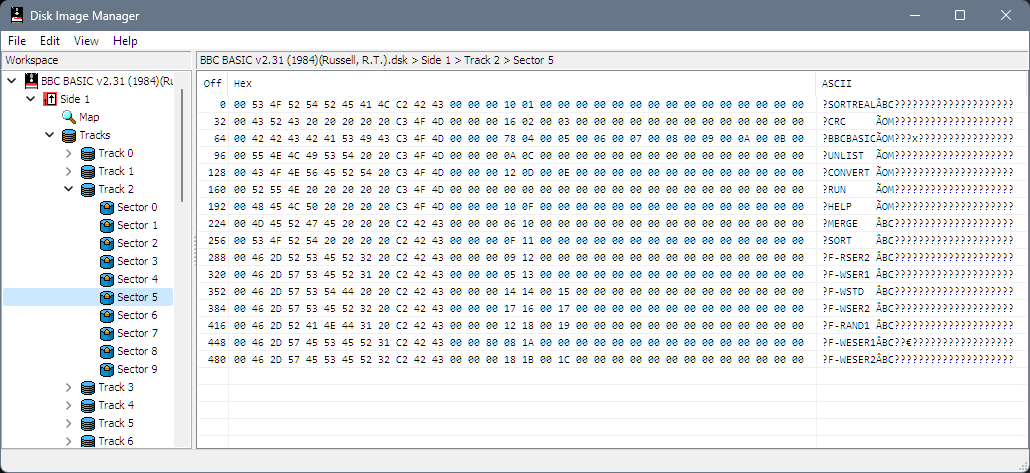
The first step was to load the DSK into Disk Image Manager and see what's inside that DSK.
This showed us the disk image is single-sided and 40 tracks (we knew that from the hardware spec) but also that there are 10 sectors per track (the Spectrum +3/CPC and PCW 3" disks used 9) and fairly typical 512 byte sectors.
With only the raw IMG this would have been harder to determine especially as I could find no information online about the Einstein's disk format either through the simple Google search or using Archive.org to search through hundreds of thousands of scanned and OCR'ed magazines and manuals. The latter is a gold-mine often missed by retro enthusiasts looking for information.
2. Locating the file allocation table (FAT)
Now we know a little about the disk the next step is to find where the file allocation table (FAT) lives. The FAT will contain a list of entries - typically 32 bytes each for CP/M-influenced systems - that contain the file name, extension, how big the file is as well as which sectors on the disk belong to this file. For space and efficiency sectors are grouped together into blocks known as allocation units - something you'll still see today when you format an SSD on modern systems.
These file allocation tables are normally easy to find as they contain the filenames but sometimes that might look to be corrupt this can be either if it is deleted - sometimes they null out the first character - or if there are flags set on files like system, read-only or archive where they tend to use a high-bit on part of the file extension to save space (file names had to be pure ASCII with codes under 127 anyway).
On a +3 this can be usually found at track 1 sector 0 right after the reserved track while the CPC Data format puts it at track 0 sector 0 but paging through the disk image Kevin sent I found it at track 2 sector 0 which made sense. Two reserved tracks, probably enough for system boot loader into the OS.
At this point I decided to check out some more Einstein images I found online but they all had the FAT track 2 sector 5... This initially confused me until I realised that the sector ID - the actual number the real machines use to identify sectors - for sector 0 was 5 and that yes the real sector 0 was stored at 5. I'm not sure whether this was a result of the imaging process itself (CPCDiskXP 1.6 was used) or whether the Einstein formatted disks this way. Sector numbers are often non-sequential to ensure that the machine has time to process the sector before the next one spins by so interleaves them (sector interleave) which speeds things up. This here was not the case tho as it was per-track (sector skew) but that's a question for another day.
3. How the disk is organized
The FAT contained 20 files spread over these two sectors and then two empty uninitialized sectors before we started to see data which indicates to me that this FAT covers 4 sectors. My first thought was 1K block sizes and 2 blocks just like the +3 but then I decided to go hunting and came across the source code for CP/M 3.1 on the Einstein which would be incredibly useful given how little low-level technical information about the Einstein that exists online.
Hidden in a innocently named config.g is the following snippet
unsigned char dpb[4][17] = {
{ 0x28, 0x00, 0x04, 0x0f, 0x00, 0x01, 0x01, 0x3f,0x00,
0x80, 0x00, 0x10, 0x00, 0x02, 0x00, 0x02, 0x03 },
{ 0x50, 0x00, 0x04, 0x0f, 0x01, 0xc7, 0x00, 0x3f,0x00,
0x80, 0x00, 0x10, 0x00, 0x00, 0x00, 0x02, 0x03 },
{ 0x28, 0x00, 0x04, 0x0f, 0x01, 0xc7, 0x00, 0x3f,0x00,
0x80, 0x00, 0x10, 0x00, 0x00, 0x00, 0x02, 0x03 },
{ 0x50, 0x00, 0x04, 0x0f, 0x00, 0x8f, 0x01, 0x7f,0x00,
0xc0, 0x00, 0x20, 0x00, 0x00, 0x00, 0x02, 0x03 } };
The DPB is the disk parameter block which describes to CP/M operating systems a little about how the disk is organized. The menu later in the program indicates the first is for 40 track single-sided, then double-sided followed by 80 track single-sided and 80 track double-sided so we only need the first entry, let's map it into a CP/M 3.1 DPB.
DEFW spt = 0x0028 ; Number of 128-byte records per track
DEFB bsh = 0x04 ; Block shift. 3 => 1k, 4 => 2k, 5 => 4k....
DEFB blm = 0x0f ; Block mask. 7 => 1k, 0Fh => 2k, 1Fh => 4k...
DEFB exm = 0x00 ; Extent mask, see later
DEFW dsm = 0x0101 ; (no. of blocks on the disc)-1
DEFW drm = 0x003f ; (no. of directory entries)-1
DEFB al0 = 0x00 ; Directory allocation bitmap, first byte
DEFB al1 = 0x80 ; Directory allocation bitmap, second byte
DEFW cks = 0x0010 ; Checksum vector size, 0 or 8000h for a fixed disc.
; No. directory entries/4, rounded up.
DEFW off = 0x0002 ; Offset, number of reserved tracks
DEFB psh = 0x02 ; Physical sector shift, 0 => 128-byte sectors
; 1 => 256-byte sectors 2 => 512-byte sectors...
DEFB phm = 0x03 ; Physical sector mask, 0 => 128-byte sectors
; 1 => 256-byte sectors, 3 => 512-byte sectors...
Okay, this is good. We can see there the reserved two tracks before the FAT which we already knew but importantly here we know that the block size is 2K and that there is 1 directory block unlike the +3 with its 1K and 2 directory blocks.
Why does that matter if the number of sectors used and file entries available is the same? Well, we need to know about that list of blocks each file uses and here we now know they are 2K blocks not 1K.
Now there is something in this DPB however that doesn't add up and that will cause us trouble later!
4. Decoding the FAT
Looking here is the FAT I found on the BBC BASIC disk image which clearly shows the FAT in a CP/M format, specifically for each entry (also called an extent) in this table we have:
- Byte 0: Specifies user area for 0-16 with some special meanings like disk labels above that
- Bytes 1-8: Specifies file name in plain ASCII (always upper-case)
- Bytes 9-11: Specifies the file extension with the high-bit possibly set (read-only, system file, archive)
- Byte 12: Extent number from 0-31 for files bigger than the allocation list for this entry would permit
- Byte 13: How many bytes used in the last record
- Byte 14: Extent number multiplier by 32 for extents > 31 (done this way for backward compatibility)
- Byte 15: How many records (128 byte entries) are used by this extent
- Bytes 16-32: List of allocation blocks either in 8-bit or 16-bit little endian format
Off Hex ASCII
0 00 53 4F 52 54 52 45 41 4C C2 42 43 00 00 00 10 SORTREALÂBC?????
16 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ????????????????
32 00 43 52 43 20 20 20 20 20 C3 4F 4D 00 00 00 16 ?CRC ÃOM????
48 02 00 03 00 00 00 00 00 00 00 00 00 00 00 00 00 ????????????????
64 00 42 42 43 42 41 53 49 43 C3 4F 4D 00 00 00 78 ?BBCBASICÃOM???x
80 04 00 05 00 06 00 07 00 08 00 09 00 0A 00 0B 00 ????????????????
96 00 55 4E 4C 49 53 54 20 20 C3 4F 4D 00 00 00 0A ?UNLIST ÃOM????
112 0C 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ????????????????
...
So looking at this for the first file we get:
- User: 0
- Filename: SORTREAL
- Extension: BBC
- Flags: Read-Only
- Extent: 0
- Bytes used: 0 (odd)
- Extent number multiplier: 0
- Records: 0x10 (16 so 2K allocated)
- Allocation blocks: 0x001
It was at this point my original plan for writing an extract tool took a detour. If this is CP/M enough perhaps we can use an existing CP/M extraction tool?
5. Hello cpmtools
There are a few tools out there but we'll be using cpmtools as it has some simple commands and most critically allows us to tell it about new disk formats.
A quick apt-get install cpmtools and we have access to cpmls to list the contents of an image and cpmcp to copy files to and from the disks but first we need to tell it about our Tatung Einstein format.
We do that by editing the diskdefs file with sudo nano /etc/cpmtools/diskdefs and logically we would add the following text to match the DPB:
diskdef einstein
seclen 512
tracks 40
sectrk 10
blocksize 2048
maxdir 64
skew 1
boottrk 2
os 2
end
Now we can do this:
cpmls -F -f einstein myimage.dsk
And hopefully see a good-looking directory. In our case we did on the image Kevin prepared but not on the ones I downloaded such as the BBC Basic. This is almost certainly because cpmtools is using the physical position of the sector within a track rather than correctly relying on the sector IDs. We can use another tool to work around this.
6. Quick detour to SAMdisk
SAMdisk from Simon Owen is a fantastic tool for disk imaging and besides being able to read and write to real floppies it can also perform a number of conversions including from flux images produced by the Kryoflux. It does a better job of creating DSKs from copy-protected disks than anything else. My preference for imaging is going over once with a flux imager and saving the files in flux then converting it to the intended format with SAMdisk.
For our purposes though we just need to de-skew those sectors for cpmtools to understand. We'll just convert the DSK file to a RAW image such as produced by tools like dd in Linux.
samdisk copy myimage.dsk myimage.raw
7. Back to cpmtools
Okay, now when we perform our cpmls we get this:
Directory For Drive A: User 0
Name Bytes Recs Attributes Prot
------------ ------ ------ ------------ ------
ANIMAL BBC 4k 24 R None
ANIMAL DAT 2k 10 None
BBCBASIC COM 16k 120 R None
BBCBASIC HLP 26k 200 R None
CONVERT COM 4k 18 R None
CRC COM 4k 22 R None
CRCKLIST CRC 2k 9 None
F-INDEX BBC 8k 53 R None
F-RAND0 BBC 2k 11 R None
F-RAND1 BBC 4k 18 R None
F-RAND2 BBC 8k 61 R None
F-RSER1 BBC 2k 3 R None
F-RSER2 BBC 2k 9 R None
F-RSTD BBC 2k 9 R None
F-WESER1 BBC 2k 8 R None
F-WESER2 BBC 4k 24 R None
F-WSER1 BBC 2k 5 R None
F-WSER2 BBC 4k 23 R None
F-WSTD BBC 4k 20 R None
HELP COM 2k 16 R None
HELP HLP 8k 53 R None
MERGE BBC 2k 6 R None
READ ME 4k 18 R None
RUN COM 2k 1 R None
SETTIME BBC 2k 8 R None
SORT BBC 2k 15 R None
SORTREAL BBC 2k 16 R None
UNLIST COM 2k 10 R None
Total Bytes = 99k Total Records = 790 Files Found = 28
Total 1k Blocks = 126 Used/Max Dir Entries For Drive A: 29/ 64
Perfect. Sensible-looking file-names, flags, sizes and records. Let's copy some files!
mkdir extracted
cpmcp -f einstein myimage.raw 0:* extracted/
Note that the 0: is required for user area 0 which is almost always the one you want. If any other user area shows in the cpmls command also copy those (file names might be duplicated between user areas tho so you'd only get one of them).
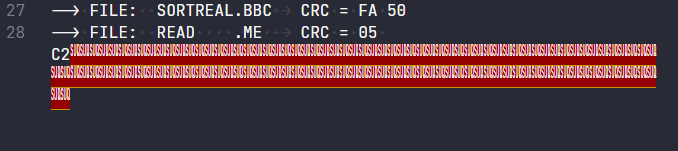
We first look at a file and.... there's blank information in the middle of the file. A ton of nulls confirmed by my hex editor. And I'm missing data at the end of the file.
Alarm bells are going off. Something is wrong with the allocation block list. If I look at them in a trusty hex view I can clearly see we have a valid block number followed by a zero then another block number followed by a zero. They're also counting up sequentially so they are very likely correct.
What's surprising is those 0's. A file allocation table can be either 8-bit (so no zeros in the middle) or 16-bit (zeroes after a lot of the bytes until they get too large for a byte).
The operating system determines whether to use 8 or 16-bit allocation entries by looking at the number of blocks on the disk. If it's less than 256 then it uses 8-bit allocation blocks. If it's more than 256 then it uses 16-bit allocation blocks so we calculate...
40 tracks _ 10 sectors _ 512 bytes per sector / 2048 block size = 100 blocks.
So why does the Einstein format use 16-bit allocation blocks? I suspect it might be a mistake in transposing 100 decimal into 0x0101 hex in the DPB or maybe it was fully intentional for compatibility with something else (but not CP/M it seems). Either way cpmtools is not happy and there isn't a setting we can use.
8. A silly hack
So given we can't force cpmtools to use a 16-bit allocation block or directly specify the number of blocks to influence that choice like the DPB was doing is there anything we CAN do?
But we have an ace up our sleeve.
diskdef einstein
seclen 512
tracks 103
sectrk 10
blocksize 2048
maxdir 64
skew 1
boottrk 2
os 2
end
By telling cpmtools there are 103 tracks on the disk it will calculate there are 257 blocks and use 16-bit allocation block numbers. This works fine for us reading data off a disk as there can't possibly be blocks pointing that high up onto the (non-existent) parts of the disk.
Be very careful though about writing! You could easily write beyond the actual disk definition or end up with a disk image you can no longer read into an emulator or write back to the einstein.
9. File endings
After all that we can now extract those files and they look good! The text files however have a 0x1A character towards the end and then some duplicate text from before the 0x1A.
0x1A is SUB/substitute in the ASCII table but back in the CP/M days it was used as a "soft-eof" character to indicate the end of file. As cpmtools doesn't listen to this (it can't know if it's ASCII or binary) anything beyond this character in text files can be safely trimmed off.
10. Going forward
I have expanded my Disk Image Manager tool to understand Einstein format disks as well as provide single and bulk file export from disk images whether they be Einstein, CPC, PCW or +3 format (or presumably another CP/M format, untested!) - simply right click the files in the files window and choose the relevant Save option!
In the mean time keep an eye on Kevin Edwards Mastodon for announcements and details as to what games the source code has been recovered for!
0 responses