Development articles (167)
HTML5 Video Cheatsheet: Optimizing videos for the web
Creating videos for your page can be tricky, especially if you ensure your videos load quickly, play smoothly, auto start, and work across all devices and browsers.

Transactions in the MongoDB EF Core Provider
Database transactions ensure that multi-record (or in our case multi-document) operations either all succeed or all fail together.
Queryable Encryption with the MongoDB EF Core Provider
MongoDB's Queryable Encryption lets you encrypt sensitive database fields while keeping them searchable. Unlike traditional encryption-at-rest that renders data unreadable to the database, queryable encryption supports equality and range queries on encrypted fields without requiring decryption first.
Lazy Loading with EF Core Proxies
With the Microsoft.EntityFrameworkCore.Proxies NuGet package you can use to traverse navigation properties. This is often preferable to joins and includes such as when using one-to-many or only exploring a subset of the navigations based on client-side logic or for providers that don't support include yet.
Enhancing content articles in Nuxt3
I've already covered reading time and generated excerpts for Nuxt3 content but there are still a couple more things you can do to enhance your content articles.
Generated Excerpts for Nuxt3 Content
Nuxt3 has been my stack of choice for a while now and it was time to port my site over from Nuxt2 - an exercise in itself I should blog about - but more concretely is the idea of excerpts.
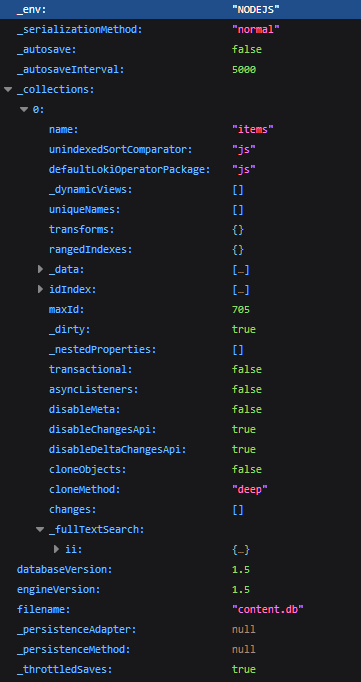
Nuxt Content v1 content.db database & file size
An examination of Nuxt's content.db and how to shrink it for performance.
Email form sender with AWS Lambda, Brevo & reCAPTCHA
In this article I'll show you how to use AWS Lambda to send an email with Brevo using their API while being protected by reCAPTCHA.
A blog comment receiver for Cloudflare Workers
A number of years back I switched to a static site generator for damieng.com, firstly with Jekyll, and then with Nuxt when I wanted more flexibility. I've been happy with the results and the site is now faster, cheaper, more secure and easier for me to maintain.
Email form sender with Nuxt3, Cloudflare, Brevo & reCAPTCHA
I've been using Nuxt quite extensively on the static sites I work on and host and use Cloudflare Pages to host them. It's a great combination of power, flexibility, performance and cost (free).
Rendering content with Nuxt3
I've been a big fan of Nuxt2 and Nuxt3 is definitely a learning curve and I have to admit the documentation is a bit lacking - lots of small fragments and many different ways to do things.
Adding reading time to Nuxt3 content
I've been using Nuxt2 quite a bit for my sites (including this one) and am now starting to use Nuxt3 for a few new ones and am finding the docs lacking in many places or confusing in others so hope to post a few more tips in the coming weeks.
Software
Writing creating computer software is my passion in life and I've been lucky to work on some incredible projects and technologies over the years.
Estimating JSON size
I've been working on a system that heavily uses message queuing (RabbitMQ via MassTransit specifically) and occasionally the system needs to deal with large object graphs that need to be processed different - either broken into smaller pieces of work or serialized to an external source and a pointer put into the message instead.
Migrating from OpenTracing.NET to OpenTelemetry.NET
OpenTracing is an interesting project that allows for the collection of various trace sources to be correlated together to provide a timeline of activity that can span services for reporting in a central system. They were competing with OpenCenus but have now merged to form OpenTelemetry.
Developing a great SDK: Guidelines & Principles
A good SDK builds on the fundamentals of good software engineering but SDKs have additional requirements to consider.
Shipping breaking changes
Breaking changes are always work for your users. Work you are forcing them to do when they upgrade to your new version. They took a dependency on your library or software because it saved them time but now it's costing them time.
Creating OR expressions in LINQ
As everybody who has read my blog before knows, I love LINQ and miss it when coding in other languages, so it's nice when I get a chance to use it again. When I come back to it with fresh eyes, I notice some things aren't as easy as they should be - and this time is no exception.
From CircleCI to GitHub Actions for Jekyll publishing
I've been a big fan of static site generation since I switched from WordPress to Jekyll back in 2018. I'm also a big fan of learning new technologies as they come along, and now GitHub Actions are out in the wild; I thought this would be an opportunity to see how I can port my existing custom CircleCI build to Jekyll.
My own Delphi story - celebrating 25 years
It's 1995, and a wiry-looking engineer in need of a haircut is working at a tech services company in the Channel Islands. The island is Jersey (you can see the French coastline on a clear day), and he's over here for a week or two for training from his nearby Guernsey home.
SemVer is an intent - not a promise
Why semantic versioning can never truly guarantee non-breaking changes, with concrete examples of how a 'safe' addition can still break consumers, and an argument for treating SemVer as an aspirational intent rather than a contract.
WordPress to Jekyll part 6 - A faster build
My site goes back to 2004 and is reasonably sized but not massive even with the comments, so waiting 30 seconds for a change to reflect is disappointing.
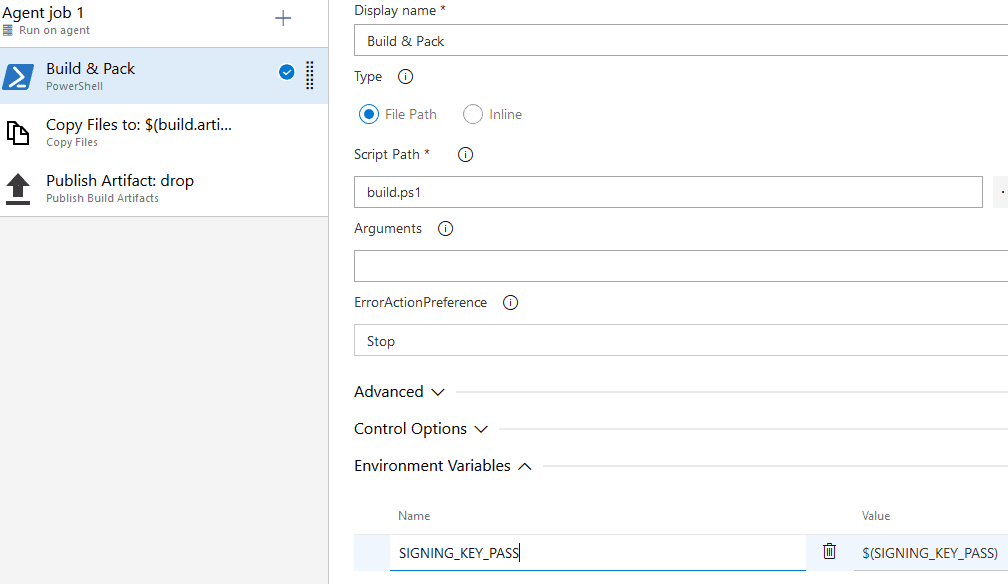
Azure Pipeline Build Variables
Azure Pipelines has been interesting to me especially given the generous free open source tier and seemingly instant availability of build agents. The setup is easy if you're building .NET targets with lots of useful starters available.
WordPress to Jekyll part 5 - Hosting & building
The next stage is considering where to host the site and whether to use a content delivery network (CDN). My preferred approach on other sites has been to:
WordPress to Jekyll part 4 - Categories and tags
Jekyll does support categories and tags directly but doesn't support the pagination of categories and tag list pages. The Paginate-v2 gem does solve this - and also lets you tweak the URL format.
WordPress to Jekyll part 3 - Site search
Site search is a feature that WordPress got right. Analytics also tells me it is popular. A static site is at a disadvantage, but we have some options to address that.
WordPress to Jekyll part 2 - Comments & commenting
I do enjoy discussion and debate, whether designing software or writing articles. Many times the comments have explored the subject further or offered corrections or additional insights and tips. They are vital on my blog, and I was disappointed that Jekyll provides nothing out of the box to handle them.
WordPress to Jekyll part 1 - My history and reasoning
It's hard to believe it was 13 years ago, back in a cold December on the little island of Guernsey, when I decided to start blogging. I'd had a static site with a few odd musings since 2000, but this was to be more regularly updated and with technical content. Blogspot seemed the easiest way to get started.
Comma-separated parameter values in WebAPI
The model binding mechanism in ASP.NET is slick - it's highly extensible and built on TypeDescriptor for re-use that lets you avoid writing boilerplate code to map between CLR objects and their web representations.
Model binding form posts to immutable objects
I've been working on porting over my blog to a static site generator. I fired up an Azure Function to handle the form-comment to PR process to enable user comments to still be part of the site without using a 3rd party commenting system - more on that in the next post - and found the ASP.NET model binding for form posts distinctly lacking.
Differences between Azure Functions v1 and v2 in C#
I've been messing around in the .NET ecosystem again, jumping back in with Azure Functions (similar to AWS Lambda) to get my blog onto 99% static hosting. I immediately ran into the API changes between v1 and v2 (currently in beta).
Download files with progress in Electron via window.fetch
Working on Atom lately, I need to be able to download files to disk. We have ways to achieve this, but they do not show the download progress. This leads to confusion and sometimes frustration on larger downloads such as updates or large packages.
Random tips for PowerShell, Bash & AWS
Now that I am again freelancing, I find myself solving unusual issues, many of which had no online solutions.
Time window events with Apache Spark Streaming
If you’re working with Spark Streaming, you might run into an interesting problem if you want to output an event based on multiple messages within a specific time period.
Table per hierarchy in Azure Table Storage
If you’re coming from an ORM background to Azure Table Storage, you might be wondering how to map class hierarchies to tables.
Sequence averages in Scala
I’ve been learning Scala and decided to put together a C# to Scala cheat sheet. All is going well but then I got stuck on the equivalent of Average.
Optimizing Sum, Count, Min, Max and Average with LINQ
LINQ is a great tool for C# programmers letting you use familiar syntax with a variety of back-end systems without having to learn another language or paradigm for many query operations.
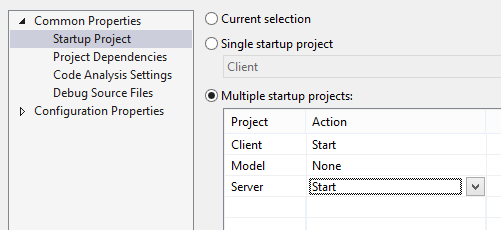
8 Visual Studio debugging tips: debug like a boss
There are so many useful debugging features built into Visual Studio that aren’t well-known. Here are a few of my favourites, including some recent finds in VS 2013.
5 simple steps to publishing a NuGet package
There is a fair amount of info on making and publishing NuGet packages but I couldn’t find a simplified guide for the simple case. Here it is and start by downloading nuget.exe and putting it in your path.
Probable C# 6.0 features illustrated
Before-and-after code samples for the probable C# 6.0 features Mads Torgersen presented at NDC London 2013, with my thoughts and questions on each one.
8 things you probably didn’t know about C#
Here’s a few unusual things about C# that few C# developers seem to know about.
Designing a great API
Several years ago I worked on a payroll package developing a core engine that required an API to let third parties write calculations, validations and security gates that would execute as part of its regular operation.
Behind the scenes at xbox.com: RSS enabling web marketplace
A number of people were requesting additional RSS feeds for the xbox.com web marketplace. (We had just one that included all new arrivals)
Enums: Better syntax, improved performance and TryParse in NET 3.5
Recently I needed to map external data into in-memory objects. In such scenarios the TryParse methods of Int and String are useful but where is Enum.TryParse? TryParse exists in .NET 4.0 but like a lot of people I’m on .NET 3.5.
Anatomy of a good bug report
Working on the .NET Framework was an interesting but often difficult time, especially when dealing with vague or incomprehensible bug reports.
Include for LINQ to SQL (and maybe other providers)
It’s quite common that when you issue a query you’re going to want to join some additional tables.
Creating RSS feeds in ASP.NET MVC
ASP.NET MVC is the technology that brought me to Microsoft and the west-coast and it’s been fun getting to grips with it these last few weeks.

My top 5 free VS 2010 extension picks
The Visual Studio Gallery is already home to 533 tools, controls and templates for VS 2010 and this number is sure to grow once VS 2010 hits RTM and people get to grips with the extendable new editor.
LINQ to SQL tips and tricks #3
Another set of useful and lesser-known LINQ to SQL techniques.
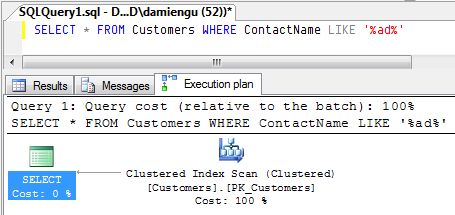
SQL Server query plan cache: what is it and why should you care?
SQL Server like all databases goes through a number of steps when it receives a command. Besides parsing and validating the command text and parameters it looks at the database schema, statistics and indexes to come up with a plan to efficiently query or change your data.
Multiple outputs from T4 made easy: revisited
My multiple outputs from t4 made easy post contained a class making it easy to produce multiple files from Visual Studio’s text templating engine (T4).
When an object-relational mapper is too much, DataReader too little
I fired up Visual Studio this evening to write a proof-of-concept app and found myself wanting strongly typed domain objects from a database but without the overhead of an object-relational mapper (the application is read-only).

LINQ to SQL cheat sheet
A two-page PDF reference for LINQ to SQL — one page for C# and one for VB.NET — covering common query operations, manipulations, and attributes.
Dictionary<T> look-up or create made simpler
The design of a Dictionary<T> lends itself well to a caching or identification mechanism and as a result you often see code that looks like this:
Client-side properties and any remote LINQ provider
David Fowler on the ASP.NET team and I have been bouncing ideas about how to solve an annoyance using LINQ:
LINQ to SQL resources
A quick round-up of some useful LINQ to SQL related resources that are available for developers. I’ve not used everything on this list myself so don’t take this as personal endorsement.
LINQ to SQL changes in .NET 4.0
People have been asking via Twitter and the LINQ to SQL forums so here’s a list I put together on a number of the changes made for 4.0.
LINQ to SQL tips and tricks #2
A few more useful and lesser-known tips for using LINQ to SQL.
LINQ to SQL tips and tricks #1
Being on the inside of a product team often leads to uncovering or stumbling upon lesser-known techniques, and here are a few little nuggets I found interesting. I have more if there is interest.
Multiple outputs from T4 made easy
A reusable Manager helper class for T4 templates that lets you split generated output into a file per block, for example one file per entity, with shared header and footer support.
LINQ to SQL templates updated, now on CodePlex
My templates that allow you to customize the LINQ to SQL code-generation process (normally performed by SQLMetal/LINQ to SQL classes designer) have been updated once again.
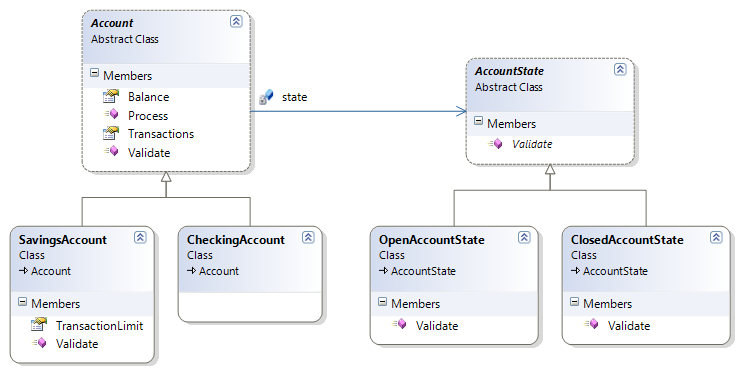
Changing type, the state pattern and LINQ to SQL
A question I see from time-to-time on LINQ to SQL relates to changing an entity’s class.
ALT.NET Seattle
One of the cool things about living in Seattle is the sheer number of passionate developers around. Whether you’re dropping into offices, heading across campus for lunch, meeting downtown for music and beer or, in my case, last month taking a Saturday out to participate in ALT.NET Seattle, there are ideas, enthusiasm and discussions with great developers to be had everywhere.
LINQ to SQL next steps
There has been a flurry of posts and comments in the last 24 hours over the future of LINQ to SQL so I thought it would be interesting to provide some information on what the LINQ to SQL team have been up to and what we’re working on for .NET Framework 4.0.
LINQ to SQL template for Visual Studio 2008
Detailed reference for my T4-based LINQ to SQL template — a customisable, designer-compatible replacement for SQLMetal supporting inheritance, VB.NET, composite keys, and stored procedure CRUD with concurrency.
Ten commandments for developers
In order that applications and operating systems shall not drive users insane, thou shall:
LINQ to SQL log to debug window, file, memory or multiple writers
The Log property on a LINQ to SQL data context takes a TextWriter and streams out details of the SQL statements and parameters that are being generated and sent to the server.
LINQ to SQL T4 template reloaded
The topic of modifying the code generation phase of LINQ to SQL comes up often and the limited T4 template I published here last month was good at showing the potential but wasn’t a practical replacement for the code generation phase.
AnkhSVN 2.0: free Subversion integration with Visual Studio
The guys over on the AnkhSVN team have acquired new members and burnt the midnight oil to deliver a great 2.0 release with:
Experimental LINQ to SQL template
A 369-line T4 template that generates a LINQ to SQL DataContext and entity classes from a SQL Server schema, offered as a proof-of-concept alternative to the un-customisable SQLMetal tool.

Localizing MVC for ASP.NET views and master pages
Microsoft’s MVC for ASP.NET is still under serious development but at the moment support for localization is a little weak. Here’s one approach that works with the 04/16 source-drop.
Using LINQ to foreach over an enum in C#
A tiny LINQ-powered helper that lets you foreach over enum values in C# without the verbose `Enum.GetValues(typeof(X)).Cast<X>()` incantation.
Safari 3.1 includes developer tools
Safari 3.1 has just been released and besides the partial CSS3 (fonts) and partial HTML5 (media tags, off-line storage) support there are some new developer tools included.
Testing web sites with the iPhone SDK
Apple’s iPhone SDK is now available in beta format for free download (running your apps on a real iPhone is a one-time $99 charge).
Future of AnkhSVN (Subversion for Visual Studio)
Road-map for the AnkhSVN 2.0 release covering Subversion 1.5 branch and merge tracking, an interactive log window, property editing, the switch to Visual Studio's source provider model, and SharpSvn for a smaller code-base.
DLookup for Excel
I had to do a couple of ad-hoc Excel jobs today and found that while Excel has a VLookup function for spreadsheet/ranges it doesn’t have one for databases.
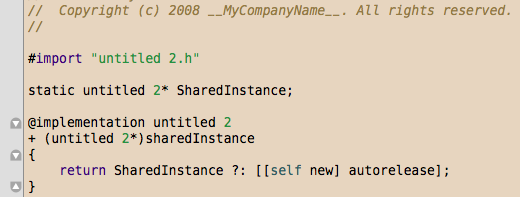
Humane theme for TextMate and Xcode
My Humane theme for Visual Studio is getting a fair bit of traffic today courtesy of Scott Hanselman. Given I have been messing with Mac development lately I thought it was worth porting to TextMate and Xcode 3.
Web site vs web application in Visual Studio
Rob Conery got me thinking about web site maintenance and I put forward a brief comment on the two distinct types and how Visual Studio handles them which I have expanded upon here.
Where developer is succinct
Radio 4 covered the The Six Word Memoir competition, inspired by Earnest Hemingway’s wager he could tell a complete story in just six words. He deliciously delivered “For sale: Baby shoes, never worn” earning him $10.
The pragmatic .NET developer
Long-time friend, fellow co-host of the GSDF and the coding genius behind the open-source Ogre3D engine Steve Streeting has written an interesting piece on Open source adoption; countering the fear and doubt. I have no doubt that this was fueled by a lengthy discussion last night in the Ship & Crown pub, a common ritual after our GSDF meetings.
Language Integrated Query: An introduction presentation online
This evening’s presentation on Language Integrated Query (LINQ) is now available from my appearances page.
Talks & podcast appearances
Here are presentations I have given as well as videos and podcasts I have appeared on.
Language Integrated Query: An introduction talk tomorrow
I’m just finishing up the slides, notes and writing code samples for my LINQ presentation at the Guernsey Software Developer Forum tomorrow evening.
LINQ presentation at Guernsey Developer Forum
I will be giving a talk at the Guernsey Software Developer Forum at the end of the month on Microsoft’s new Language Integrated Query (LINQ) with particular emphasis on the capabilities and object-relational mapping characteristics of LINQ to SQL.
Thoughts on awareness of security vulnerabilities & full disclosure
HTML, SQL and XSS injection vulnerabilities aren’t new but they are still largely ignored by developers.
5 signs your ASP.NET application may be vulnerable to HTML injection
If you don’t encode data when using any of the following methods to output to HTML your application could be compromised by unexpected HTML turning up in the page and modifying everything from formatting though to capturing and interfering with form data via remote scripts (XSS). Such vulnerabilities are incredibly dangerous.
ASP.NET MVC preview available
The first public preview of Microsoft’s ASP.NET MVC (model view controller) framework is now available.
Free software projects need a pitch
Open source and free software projects still have much to learn from commercial software, the number one in my book being “the pitch”.
Shrinking JS or CSS is premature optimization
Rick Strahl has a post on a JavaScript minifier utility the sole job of which is to shrink the size of your JavaScript while making it almost impossible to read in order to save a few kilobytes.I thought I’d take a quick look at what the gain would be and fed it the latest version (1.6) of the very popular Prototype library:
Calculating Elf-32 in C# and .NET
A C# implementation of the elf_hash function used by the Executable and Linkable Format, packaged as a System.Security.Cryptography.HashAlgorithm subclass.
Publishing .NET applications with prerequisites
Now .NET 3.5 is shipping I took the opportunity to update one of our internal applications and elected to have it install the necessary components (in this case the .NET Framework 3.5) using the Download prerequisites from the same location as my application option.
Calculating CRC-64 in C# and .NET
Seeing how the CRC-32 C# class I posted some time ago continues to get lots of Google hits I thought I’d post a CRC-64 version which will no doubt be far less popular being the more limited use. Again, do not use this as a secure message signature, it’s really for backward compatibility with legacy systems.

Silk Icons Companion #1 (more Silk icons)
Mark James (FamFamFam) created a great set of 1,022 silky-smooth 16x16 true-colour icons in PNG format, aptly named Silk Icons.
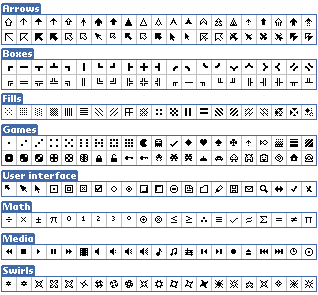
Titchy icons
Paul Dunn, the man behind the Spectrum emulator-IDE combo known as BASin, asked me to contribute fonts and UDG's (icons) to the package for users to be able to reuse in their own creations.
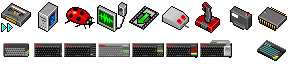
Icons
I have pushed pixels for a number of applications, sites and sets.

Dissecting a C# Application: Inside SharpDevelop
This great book shows you the process, thinking and code behind the open-source .NET IDE SharpDevelop that went on to branch into MonoDevelop.
Using GUIDs as row identifiers
Wade Wright is preaching that IDs in a database should always be GUIDs and lists four reasons. I commented there with my opinions but it hasn’t shown up. Some people like to censor if you don’t agree with them completely. My points addressing each of his four ‘reasons’ were:
Object Initializers in .NET 3.5
One compiler improvement in .NET 3.5 is the object initializers feature that lets you concisely set properties of an object as you create it.
Security vulnerabilities are not acceptable in sample code
Earlier this week the ASP.NET article of the day linked to 4-Tier Architecture in ASP.NET with C# which I noticed suffered from both HTML and SQL injection. I promptly informed the author and the ASP.NET site (who pulled the link) but the author was unconcerned and wrote (after editing my comment):
Extension methods illustrated
Extension methods are a great new feature in the .NET Framework 3.5 that let you write new methods that appear to be part of existing classes without the need to subclass or modify them.
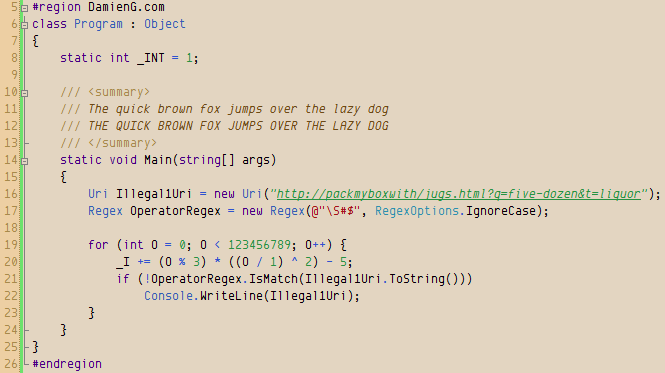
Color schemes for Visual Studio
The default syntax color scheme in Visual Studio seems to be stuck in the 16-color era so once you’ve found your perfect font you are going to need a great theme to go with it.
Observations on Microsoft MVC for ASP.NET
Anyone who’s tried to develop large complex web sites with ASP.NET has likely run into many problems covering the page and control life cycle, view state and post backs and subsequent maintainability including the difficulty in creating automated unit tests.
Refactoring shared libraries and public APIs
Refactoring is an essential process to keep code clean and elegant while it evolves. IDE’s offer common refactorings (although somewhat short of those prescribed in Fowler’s excellent Refactoring book and way short of the overall goals explained in Kerievsky’s Refactoring Patterns).
LINQ in 60 seconds
Microsoft’s Language INtegrated Query (LINQ) aims to provide a way of selecting objects with a common syntax independent of the data source.
Softography
This list represents some of the highlights I've had the pleasure of developing, extending or otherwise contributing significantly to.
Investigating MonoRail
First impressions evaluating Castle MonoRail as an alternative to ASP.NET WebForms — what it gets right, what's missing for a strong-typing C# developer, and the discovery that the built-in grid component happily injects unescaped HTML.
Web Application Security for Developers presentation
Last nights Guernsey Software Developers Forum meeting was sparsely attended with a number of the regulars attendees absent. There were however two new faces including Kezzer who I’d been chatting to on-line for years.
Multiple-inheritance, composition and single responsibility principle in .NET
.NET is often chided by C++ developers for failing to support multiple-inheritance. The reply is often Favor object composition over class inheritance, a mantra chanted from everywhere including the opening chapters of the Gang of Four’s Design Patterns book.
Typed session data in ASP.NET made easier still
Philippe Leybaert is unimpressed with Microsoft’s Web Client Software Factory approach for typed session data and offers his own Typed session data made (very) easy which still seems overkill to me comprising as it does of generics, a delegate a helper class to achieve the desired effect. (While you are there check out his very interesting MVC project for ASP.NET called ProMesh)
Partial methods in .NET 3.5, overview and evolution
One of the interesting new things in .NET 3.5 is partial methods which are now being used extensively by LINQ to SQL and no-doubt will be Microsoft’s corner-post of extensibility for generated classes. Here’s a quick overview:
Rails-style controllers for ASP.NET
Rob Conery has been putting together some great screen casts on SubSonic and his latest on generating controllers pointed out that ASP.NET doesn’t support the Rails-style http://site//controller/method style of execution.
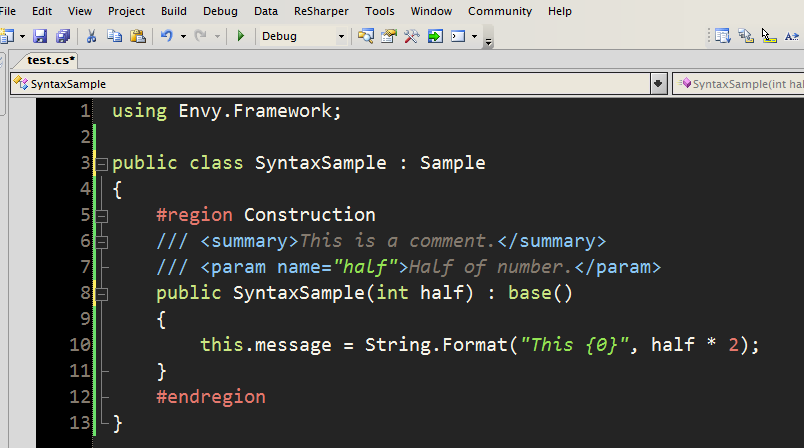
Italic syntax highlighting in Visual Studio 2005
I came across a posting by Thomas Restrepo about a theme for Vim he likes called Wombat and how it wouldn’t be worth porting to Visual Studio as it doesn’t support italic syntax highlighting, as we all know.
Getting started with Ruby on Rails on Mac OS X
Step-by-step walkthrough of setting up Ruby on Rails on Mac OS X via Fink and gem, including Mongrel as the web server and MySQL 5.0 as the database, with a sample scaffold to verify the stack.
CodeSmith template to generate LINQ To SQL Data Context
If you are interested in what LINQ to SQL generates and don’t have Orcas installed or available right now but use CodeSmith try the following template to generate very similar code.
Discarding new entity objects in LINQ to SQL beta 1
An unusual bug in .NET Framework 3.5 beta 1 that relates to creating a new entity object in LINQ to SQL has been getting in my way.

DiffMerge is free, try it with AnkhSVN
SourceGear, known for their Vault source control software, are giving away their three-way diff & merge tool DiffMerge for Windows, Mac and Unix.
Safari for Windows surprises: return of YellowBox?
While Apple’s Safari appearing on Windows isn’t all that surprising given the number of Windows-related patches to WebKit/KHTML they committed back the actual release has a few surprises.
LINQ to SQL NullReferenceException on SubmitChanges
I’ve been busy working on some LINQ to SQL (formerly DLINQ) apps that have been going well bar a NullReferenceException thrown at me from deep in the bowels of LINQ and it’s change tracker. A cursory glance in debug showed none of the properties that represent columns were null…
NotifyIcon context menus for both buttons in .NET (evolution of a hack)
Here’s the evolution of what should have been a clean reusable component in .NET and how it becomes a hack thanks to the limitation of the .NET framework.
LINQ to SQL details, issues and patterns
LINQ to SQL (formerly called DLINQ) is a simple object-relational mapper (ORM) scheduled for .NET Framework 3.5/Visual Studio 2007 (Orcas).
ActiveRecord, the ugly design pattern
I first encountered the Gang of Four Design Patterns book back in 2001 when a friend lent me a copy. I didn’t immediately get it, most likely because my object oriented experience up to that point consisted primarily of small Delphi applications.
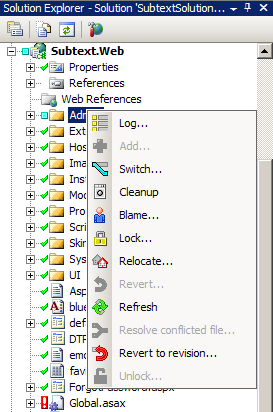
AnkhSVN 1.0 released (Subversion plug-in for Visual Studio)
Announcement of the AnkhSVN 1.0 release bringing Subversion source control directly into Visual Studio 2003 and 2005, alongside the debut of my icon set.

How to spot a Visual Studio 2005 SP1 installation
If you have a couple of machines, a few virtual machines and secondary installations such as Express editions (for XNA of course) you can easily lose track of which have been patched with service pack 1. Especially if you also messed around with the SP1 beta.
Eight things I hate about Visual Studio 2005
While Visual Studio is quite a capable IDE it isn’t perfect; here is my personal top 10 list of things I hate about it. I’ve kept the gripes to the IDE itself, and the issues I have with .NET Framework deserve a post of their own some time.
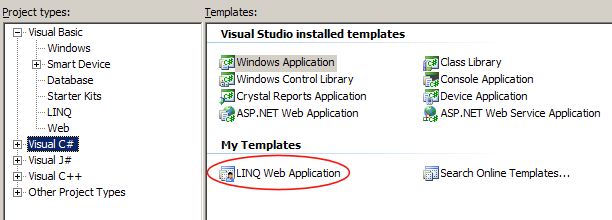
LINQ in C# Web Applications
I’m a big fan of the Web Application type that was previously available as an add-on to Visual Studio 2005 but it got promoted to a standard citizen with Service Pack 1.
My 2006 development tools
Christopher Bennage wrote about his development tool set-up and encouraged others to do the same so here’s my current set-up.
Localizing .NET web applications
It seems that globalization often makes the wish list of many a web site until the client realizes professional quality translations require a significant investment of time and money.
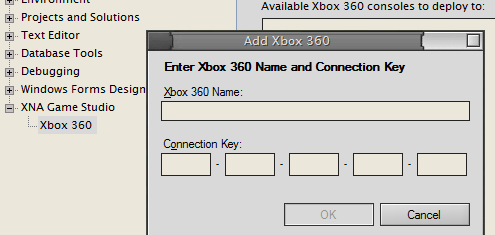
XNA Game Studio Beta 2 has Xbox 360 support
Yesterday I predicted the ability to run XNA code on our Xbox 360’s today.
WinForms tricks & tips
A short collection of C# WinForms tips, including making TreeView right-click select the node, using AppendText for fast TextBox updates, and pointing the curious at the designer-generated code for dynamic controls.
Compile XNA for your Xbox 360 tomorrow?
There’s a possibility that tomorrow will see the announcement of XNA Game Studio Beta 2 with support for compiling and running applications on your Xbox 360.
AnkhSVN 1.0 RC4 out
Notes on the AnkhSVN 1.0 RC4 release of the Subversion plug-in for Visual Studio, including fixes for delete handling and the debut of my own pixel-art icon set.
Parameterising the IN clause of an SQL SELECT in .NET
I’m a fan of parameterized queries with a strong dislike for building SQL (or other magic strings). Encoding, escaping errors, localization formatting problems and injection can run rampant when you think everything is a string.
.NET quick samples: Up-times, ages, rounding to n places
Just a few quick .NET samples for performing some common tasks that the .NET Framework doesn’t do for you:
AnkhSVN & TortoiseSVN
Announcing that I'd joined the AnkhSVN team to design a new icon set for the 1.0 release, plus a handy global ignore pattern list for use with TortoiseSVN.
Visual Studio 2005 Service Pack 1 Beta experiences
Like most people I’ve run into my fair share of oddities and problems in Visual Studio 2005 including the dreaded VB compiler dying a death on reasonable-sized projects so I jumped at the chance to get my hands on the beta of SP1.
Visual Studio tips & tricks
The Visual Studio IDE (VS2003, VS2005) is a massive beast with a plethora of options, settings and tweaks to be had.
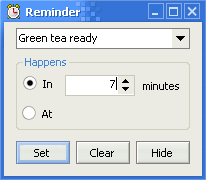
QuickReminder mini-app: Time based reminders in your system tray
Whether it’s a meeting for a specific time or remembering to stop the tea brewing in 7 minutes time (lovely tea from Adagio Teas that deserves it’s own blog post) events often whiz by without me noticing. I’m not great at time based background threading… but a computer is.
App-A-Day & SubSonic
Highlights from Dana Hanna's an-app-a-day-for-30-days C# project, plus an update on Rob Conery's SubSonic data-access toolkit and his DotNetRocks interview.
Extending GridView to access generated columns
ASP.NET’s GridView is a useful control and one of it’s best features is it’s ability to generate the columns automatically from the data source given.
Subtext .NET blogging system 1.9 released
My favorite .NET blogging system, Subtext, is celebrating it’s first .NET 2.0 compatible release known as Subtext 1.9.
XNA Game Studio Express out today
Beta 1 of Microsoft’s free XNA Game Studio Express product should be available for download later today.
Choose your ORM: Runtime, code generation or build provider?
Selecting the right object-relational mapper is a tricky decision with many factors to weigh up.
Equatable Weak References
In a previous post I described a WeakReference<T> class for providing strongly-typed WeakReference objects.
Microsoft announces XNA for homebrew, score 1 for my prediction skills
Over the last few months I’ve pieced together various snippets and hints from the web to come to the conclusion that Microsoft’s forthcoming XNA platform, specifically the XNA Framework version, would be available to home-brew developers and let them develop on the Xbox 360, the first official home-brew since the PlayStation 1’s Net Yaroze!
Calculating CRC-32 in C# and .NET
Just a few days ago I found myself needing to calculate a CRC-32 in .NET. With so many facilities available I was a little shocked that there was nothing built-in to do it so knocked up something myself.
Implementing a generic WeakReference<T> in C#
A weak reference lets you hold a reference to an object that will not prevent it from being garbage collected. There are a few scenarios where this might be important, such as listening for events, caching, various MVC patterns.
Patterns of Enterprise Application Architecture
While a big fan of patterns I found the original Gang of Four (GoF) book a little dry and so had left the pattern books alone until Martin Fowler’s Patterns of Enterprise Application Architecture (PEAA), got referenced so many times on-line I gave in and purchased a copy. I’m glad I did, even if the examples are mostly in Java with the very occasional one in C#.
Observing changes to a List<T> by adding events
In an attempt to get more C# and .NET content up I’m putting up some snippets I’ve put together in response to questions on some C# user support groups. Many of them are not particularly advanced but they are useful.
First look: Applying Domain-Driven Designs and Patterns
In an attempt to quench my thirst for all things C# and having already torn through the great .NET Framework Design Guidelines and less-great Effective C# I grabbed a copy of Applying Domain-Driven Design and Patterns (With Examples in C# and .NET) by Jimmy Nilsson.
Extend HttpApplication with session counts and uptime
It’s sometimes useful to know or display how many people are currently using your web application and how long it’s been up for.
IEnumerable<T> as IEnumerable<BaseClassOfT>
A few weeks ago I touched on the substitutability of generic types and how Collection<BaseClass> is never substitutable for Collection<SubClass>. This is because while the read facilities would be substitutable the write ones would not be. A Collection<SubClass> can’t contain non-SubClass classes.
Piecing together Microsoft’s XNA gaming platform
I’ve briefly covered Microsoft’s XNA gaming platform before but have been trying to piece together what it is actually going to mean to developers.
Substitutability of generic types in .NET
Why `obj is DamoClass<object>` doesn't behave the way you'd expect with .NET generics, and the recommended pattern of splitting a generic class into a non-generic base plus a generic subclass — the same trick .NET uses for IEnumerable.
Handling nullable value types in .NET 1.x
One of the great new features in .NET 2.0 is support for nullable types, especially important when dealing with value types such as Int or DateTime values coming from a database. Previously you were forced to either set and track another binary flag or to use a “special” value to represent null that sooner or later would turn up in real data.
Bad programming advice: don’t use exceptions
Kristian Dupont Knudsen has written a top 10 of programming advice not to follow with his rationalisation for each one. Being a programmer I thought I’d chip in with my 2 bits.
Microsoft adds embedded SQL Server Everywhere Edition to line-up
Microsoft have announced SQL Server Everywhere as part of their line-up for SQL Server.
Microsoft XNA
Microsoft have announced their XNA platform for game development.
Web applications in Visual Studio 2005
One of the things that annoyed me with Visual Studio.NET 2003 and Visual Studio 2005 is the web “project” type.
Do not expose the implementation
One of the things we are taught in object oriented design is that the outside world should not be exposed to the complexities of how our object achieves their goals. Other developers are busy, don’t care and really don’t need to know. It is a sound idea and goes hand-in-hand with ease of use.
NullableTypes 1.3.1 beta
In my early .NET days I ran into a problem many developers integrating with other systems do. Unlike XML with it’s xsl:nil or database fields with <null> the standard .NET value-types don’t support the concept of null for missing values. It’s such an important omission that Microsoft implemented it in .NET 2.0 (now gone RTM and up on MSDN) with a generics class named Nullable<T> and a little syntactic sugar to help it go down smoothly.
Automatic comparison operator overloading in C#
Abhinaba has blogged on the painful C# operator overloading experience.
Conditional operator bug in .NET 1.x & 2.0
Update: This behavior is as expected according to the .NET team but it's probably unexpected for most users.
Avoiding SQL injection
Back in ’98 I was developing an extranet site for a local company when I realized that it would be open for exploit if somebody put single quotes in text fields. It was early in the development cycle so I fixed it and moved on, unable to find out how other people were avoiding the problem.
Visual Studio 2003: System.ArgumentException in debugger
I recently ran into a problem while debugging inside Visual Studio 2003.Net. Google couldn’t find me an answer, only a few other people with the same problem. Here’s my solution in the hope it might save somebody else some time.
VB.NET to C# conversion
I recently converted some components on a project from VB.NET to C#, mainly for overloading and better tool support (such as ReSharper). Some of the existing code was generated from my own CodeSmith templates, so a small rewrite to generate C# handled most of that.
My .NET toolkit
Every developer has his own favorite set of development tools and libraries that he’s come to rely on. Here’s a round-up of some I use or am looking at.
Lapsed-listeners: Memory leaks in subscriber-publisher scenarios
I’ve been promising something .NET related for a while… here’s something!